Fsync Failures
Original Paper: Can applications recover from fsync failures?
Introduction
Paper examines the bahaviour of several filesystems and several popular data-intensive applications in the event of an fsync failure.
Following filesystems are analysed:
- ext4 (
data=orderedanddata=journal) - Btrfs
- XFS
Following data-intensive applications were analysed:
- PostgreSQL (with and without
DIRECT_IO) - LMDB
- Redis
- Sqlite
- LevelDB
File Systems Behaviour
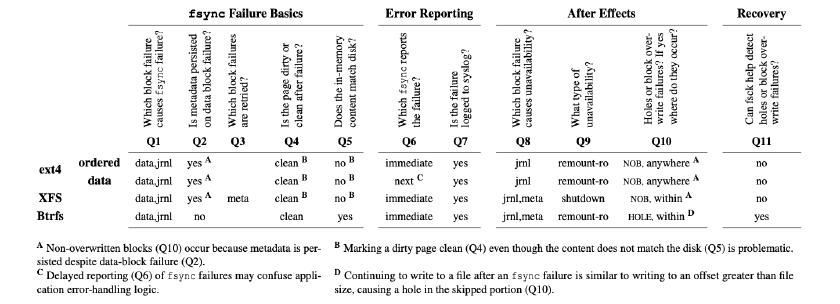
NOTE: Only examines the cases when fsync signals an EIO error.
2 kinds of “workloads” are examined:
- Single Block Update - Updating a middle page.
- Multi Block Append - Appending data to a log file opened in append mode.
Applications Behaviour
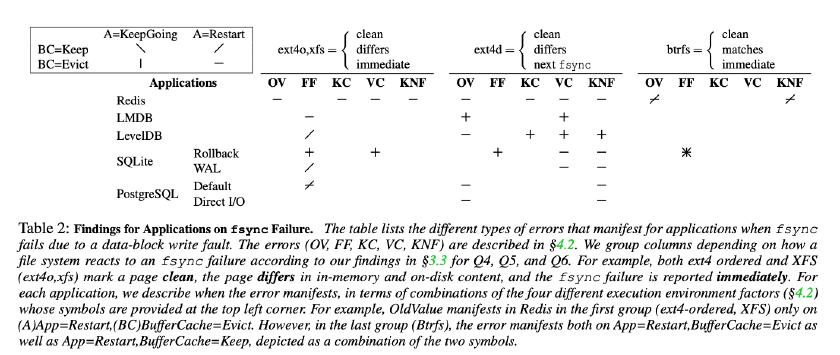
Here,
- OV: Old Value
- FF: False Failure
- KC: Key Corruption
- VC: Value Corruption
- KNF: Key Not Found
- BC: Buffer Cache (File System Cache)
- A: Application State
Takeaways
Directly copied from the paper.
#1: Existing file systems do not handle fsync failures uniformly. In an effort to hide cross-platform differences, POSIX is intentionally vague on how failures are handled. Thus, different file systems behave differently after an fsync failure (as seen in Table 1), leading to non-deterministic outcomes for applications that treat all file systems equally. We believe that the POSIX specification for fsync needs to be clarified and the expected failure behavior described in more detail.
#2: Copy-on-Write file systems such as Btrfs handle fsync failures better than existing journaling file systems like ext4 and XFS. Btrfs uses new or unused blocks when writing data to disk; the entire file system moves from one state to another on success and no in-between states are permitted. Such a strategy defends against corruptions when only some blocks contain newly written data. File systems that use copyon-write may be more generally robust to fsync failures than journaling file systems.
#3: Ext4 data mode provides a false sense of durability. Application developers sometimes choose to use a data journaling file system despite its lower performance because they believe data mode is more durable. Ext4 data mode does ensure data and metadata are in a “consistent state”, but only from the perspective of the file system. As seen in Table 2, application-level inconsistencies are still possible. Furthermore, applications cannot determine whether an error received from fsync pertains to the most recent operation or an operation sometime in the past. When failed intentions are a possibility, applications need a stronger contract with the file system, notifying them of relevant context such as data in the journal and which blocks were not successfully written.
#4: Existing file-system fault-injection tests are devoid of workloads that continue to run post failure. While all file systems perform fault-injection tests, they are mainly to ensure that the file system is consistent after encountering a failure. Such tests involve shutting down the file system soon after a fault and checking if the file system recovers correctly when restarted. We believe that file-system developers should also test workloads that continue to run post failure, and see if the effects are as intended. Such effects should then be documented. File-system developers can also quickly test the effect on certain characteristics by running those workloads on CuttleFS before changing the actual file system.
#5: Application developers write OS-specific code, but are not aware of all OS-differences. The FreeBSD VFS layer chooses to re-dirty pages when there is a failure (except when the device is removed) while Linux hands over the failure handling responsibility to the individual file systems below the VFS layer (§3.3.4). We hope that the Linux file-system maintainers will adopt a similar approach in an effort to handle fsync failures uniformly across file systems. Note that it is also important to think about when to classify whether a device has been removed. For example, while storage devices connected over a network aren’t really as permanent as local hard disks, they are more permanent than removable USB sticks. Temporary disconnects over a network need not be perceived as device removal and re-attachment; pages associated with such a device can be re-dirtied on write failure.
#6: Application developers do not target specific file systems. We observe that data-intensive applications configure their durability and error-handling strategies according to the OS they are running on, but treat all file systems on a specific operating system equally. Thus, as seen in Table 2, a single application can manifest different errors depending on the file system. If the POSIX standard is not refined, applications may wish to handle fsync failures on different file systems differently. Alternatively, applications may choose to code against failure handling characteristics as opposed to specific file systems, but this requires file systems to expose some interface to query characteristics such as “Post Failure Page State/Content” and “Immediate/Delayed Error Reporting”.
#7: Applications employ a variety of strategies when fsync fails, but none are sufficient. As seen in Section 4.3, Redis chooses to trust the file system and does not even check fsync return codes, LMDB, LevelDB, and SQLite revert in-memory state and report the error to the application while PostgreSQL chooses to crash. We have seen that none of the applications retry fsync on failure; application developers appear to be aware that pages are marked clean on fsync failure and another fsync will not flush additional data to disk. Despite the fact that applications take great care to handle a range of errors from the storage stack (e.g., LevelDB writes CRC Checksums to detect invalid log entries and SQLite updates the header of the rollback journal only after the data is persisted to it), data durability cannot be guaranteed as long as fsync errors are not handled correctly. While no one strategy is always effective, the approach currently taken by PostgreSQL to use direct IO may best handle fsync failures. If file systems do choose to report failure handling characteristics in a standard format, applications may be able to employ better strategies. For example, applications can choose to keep track of dirtied pages and re-dirty them by reading and writing back a single byte if they know that the page content is not reverted on failure (ext4, XFS). On Btrfs, one would have to keep track of the page as well as its content. For applications that access multiple files, it is important to note that the files can exist on different file systems.
#8: Applications run recovery logic that accesses incorrect data in the page cache. Applications that depend on the page cache for faster recovery are susceptible to FalseFailures. As seen in LevelDB, SQLite, and PostgreSQL, when the wal incurs an fsync failure, the applications fail the operation and notify the user; In these cases, while the on-disk state may be corrupt, the entry in the page cache is valid; thus, an application that recovers state from the wal might read partially valid entries from the page cache and incorrectly update on-disk state. Applications should read the on-disk content of files when performing recovery.
#9: Application recovery logic is not tested with low level block faults. Applications test recovery logic and possibilities of data loss by either mocking system call return codes or emulating crash-restart scenarios, limiting interaction with the underlying file system. As a result, failure handling logic by the file system is not exercised. Applications should test recovery logic using low-level block injectors that force underlying file-system error handling. Alternatively, they could use a fault injector like CuttleFS that mimics different file-system error-handling characteristics.